U.S. Army advances novel machine learning approach to coordinate drone swarms
By DE Staff
Automation DefenseHierarchical Reinforcement Learning technique cuts computation and communications complexity to reduce learning time by 80%
ARL researchers used this Clearpath Robotics Husky robot to develop a new technique to quickly teach robots novel traversal behaviors with minimal human oversight. (Photo credit: U.S. Army)
According to Dr. Jemin George of the U.S. Army Combat Capabilities Development Command’s Army Research Laboratory, the Army is looking to apply swarming technology to time-consuming or dangerous tasks.
“Finding optimal guidance policies for these swarming vehicles in real-time is a key requirement for enhancing warfighters’ tactical situational awareness, allowing the U.S. Army to dominate in a contested environment,” George said.
Their approach focuses on reinforcement learning, a type of machine learning that deals with goal-oriented algorithms that learn how to achieve a complex or long-term goal through several steps. Current schemes require data to be pooled in a centralzed “learner”, an approach that’s heavily dependent on complex computation and communication systems and thereby requires a long learning time.
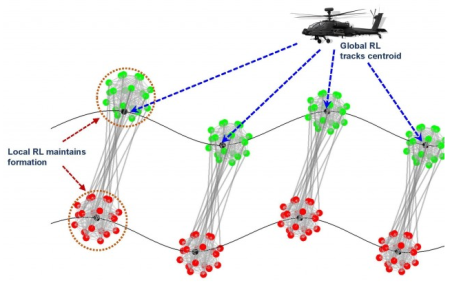
The U.S. Army researchers’ HRL machine learning concept implements hierarchical control for ground and air vehicle coordination.
(Photo credit: U.S. Army)
“Each hierarchy has its own learning loop with respective local and global reward functions,” George said. “We were able to significantly reduce the learning time by running these learning loops in parallel.”
According the research team, experiments have shown that HRL reduced learning time by 80% while limiting the optimality loss to 5% when compared to a centralized approach,
“Our current HRL efforts will allow us to develop control policies for swarms of unmanned aerial and ground vehicles so that they can optimally accomplish different mission sets even though the individual dynamics for the swarming agents are unknown,” George said.
Currently, the team is working to improve their HRL control scheme by considering optimal grouping of agents in the swarm to minimize computation and communication complexity while limiting the optimality gap.
They are also investigating the use of deep recurrent neural networks to learn and predict the best grouping patterns and the application of developed techniques for optimal coordination of autonomous air and ground vehicles in Multi-Domain Operations in dense urban terrain.
www.army.mil